

Introdução
Imagine a felicidade de iniciar um projeto de monitoramento de ativos de rede com Zabbix[i]. De fato, o manuseio básico da ferramenta hoje é tão fácil, que os primeiros resultados das coletas de dados já nos deixam quase que totalmente satisfeitos, por exemplo, ao se aplicar um template a um host e ver os dados já “brotando” nos dashboards.
Se ainda não fez, experimente! Crie um web server. Pode usar Apache ou ainda Nginx, aplicando a ele o respectivo template[ii] nativo para coleta de métricas via HTTP: “Apache by HTTP” ou “Nginx by HTTP”. Você vai notar que métricas interessantes são coletadas e logo vai conseguir criar (ou já virão criados) gráficos para consumo em dashboards. Mas é só isso? Está pronto? Não, há mais por vir.
Com o Zabbix, podemos ir além. Discutiremos nesse primeiro artigo como pensar novas métricas, novos casos, como apoiar e alcançar alguns resultados importantes para o negócio, introduzindo conceitos que muitos analistas deixam escapar por caírem na armadilha da “facilidade” e alguns outros conceitos novos, como os utilizados em alguns projetos de Ciência de Dados.
Nosso objetivo? Desbravar algumas novas funções do Zabbix surgidas a partir da versão 6.0 e apresentar modelos práticos de análise e exibição de dados, criando insights.
Contexto
Para que nosso estudo seja direcionado, manteremos o foco nas métricas de um web server, tendo em mente que o desenvolvimento sugerido aqui poderá ser aplicado em outros serviços, observando seu devido contexto.
Nosso web server roda sob nginx 1.18.0. Aplicamos o template “Nginx by HTTP”. As métricas coletadas são as seguintes:
- HTTP agent master item: get_stub_status
- Dependent items[iii]:
Nginx: Connections accepted per second
Nginx: Connections dropped per second
Nginx: Connections handled per second
- Simple check items:
Nginx: Service response time
Ok, essas são as possibilidades atuais.
Criamos um dashboard simples com base nas métricas coletadas com template nativo. O que elas podem nos dizer sobre nosso web server?
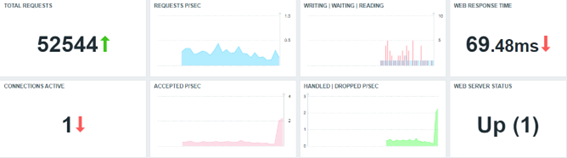
Todos os Widgets, neste caso, estão refletindo as métricas coletadas pela proposta do template padrão “Nginx by HTTP”.
Sem muitos detalhes sobre a formatação dos Widgets, existem algumas críticas que precisamos fazer, enquanto especialistas em Zabbix e com algum entendimento da aplicação que estamos monitorando. Todas as críticas, claro, são construtivas e são sugestões para implementações para agora, ou para o futuro (por exemplo, alterando o template padrão). Faremos alguns apontamentos na próxima sessão.
Reflexões para geração de novas métricas
Observando as métricas inicialmente coletadas, vamos enumerar algumas perguntas e em seguida, vamos tentar respondê-las, usando nossa série de artigos, começando por este.
- Por que o número de requisições totais apenas sobe?
- Sabemos o número de requisições ativas no momento da coleta. Temos um histórico. Podemos gerar um gráfico. Então, em que momento tivemos mais ou menos conexões em uma determinada hora. E se compararmos com a hora anterior, qual o percentual de variação?
- Qual foi o melhor ou o pior tempo de resposta na última hora, no dia de hoje, na semana, no mês ou no ano?
- Com base na observação dos tempos de resposta, podemos prever uma provável queda da aplicação?
- Podemos detectar anomalias através de um padrão de comportamento do serviço em questão?
- Seria possível estabelecer uma “baseline”? Como fazer isso?
- Se há uma baseline, é possível realizar uma comparação com o esperado x fato. Como representar essa diferença? O que ela poderia significar?
Essas são algumas de várias perguntas que podemos e devemos fazer de forma construtiva. Vejamos como responder algumas dessas questões.
Gerando novas métricas
1º passo: Clone o template “Nginx by HTTP” e crie template “Nginx by HTTP modified”.
2º passo: Entre no item “Nginx: Requests total” e na guia “Preprocessing”, adicione mais um passo ao final: “Simple change”. Deve ficar exatamente como na imagem abaixo:
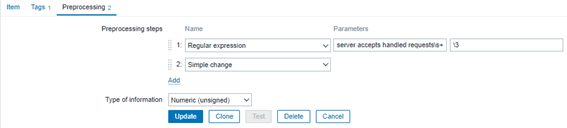
Este item é um “Dependent item” de “Nginx: Get stub status page”, o qual é coletado via HTTP agent a cada minuto. Logo, se o número de conexões apenas cresce (e só vai recomeçar quando e se o serviço Nginx for reiniciado), o valor atual será subtraído do valor anteriormente coletado, nos dando a diferença de conexões no último minuto.
A fórmula que representa o Preprocessing “Simple change” pode ser ilustrada abaixo:
Valor atual – Valor anterior = Novas Conexões
Assim, também é sugerido alterar o nome do item para “Nginx: Requests at last minute”, pois não se trata mais de um total de requisições. Agora, vamos gerar métrica de novas conexões por minuto.
Adicione também uma nova informação na guia Tag[i] do item, como na figura abaixo:

No futuro, esta tag será útil para aplicarmos um filtro nos itens que possuem monitoramento atualizado a cada minuto, por exemplo.
Variações da mesma métrica
Agora que alteramos um ponto importante no template, nosso monitoramento consegue nos dizer quantas novas conexões por minuto o web server recebeu e com isso, podemos gerar métricas para um total de conexões em blocos específicos de tempo (timeshift[i]), tais como:
- Na última hora
- Hoje, até agora
- Ontem
- Nesta semana
- Na semana anterior
- Neste mês
- No mês anterior
- Neste ano
- No ano anterior
Esse exercício pode ser interessante. Vamos criar vários items do tipo “Calculated” com as seguintes fórmulas:
sum(//nginx.requests.total,1h:now/h) # Somatório de novas conexões na hora anterior
sum(//nginx.requests.total,1h:now/h+1h) # Somatório de novas conexões da hora atual
A documentação da fabricante é crucial para que tais items sejam corretamente criados e vai ajudar também na escolha entre resgatar o valor de “history” ou de “trends”. Veja neste link.
Melhorando nosso dashboard
Com os novos valores, agora podemos deixar nosso dashboard mais interessante. Vamos dar uma espiada:

O mesmo framework pode ser usado para exibir os dados diários, semanais, anuais e suas respectivas comparações. Será necessário um pouco de paciência, nesse caso, pois se construirmos os novos items agora, levará um tempo até que alguns eles façam sua primeira coleta (o semanal, mensal ou anual, por exemplo).
Gerando estatísticas básicas
Como sabemos, é perfeitamente possível gerar algumas estatísticas básicas com o Zabbix. Algumas perguntas podem novamente nos guias para as respostas que virão em formato de métricas:
- Qual o melhor tempo de resposta que o serviço apresentou hoje?
- E quanto ao pior tempo de resposta?
- Qual a média do dia?
Vamos iniciar com estas mais básicas e avançar com outras, posteriormente.

Todas as respostas foram encontradas utilizando funções simples, como:
Melhor tempo de resposta hoje, até agora (today so far)
min(//net.tcp.service.perf[http,”{HOST.CONN}”,”{$NGINX.STUB_STATUS.PORT}”],1d:now/d+1d)
Pior tempo de resposta hoje, até agora (today so far)
max(//net.tcp.service.perf[http,”{HOST.CONN}”,”{$NGINX.STUB_STATUS.PORT}”],1d:now/d+1d)
Média Melhor tempo de resposta hoje, até agora (today so far)
avg(//net.tcp.service.perf[http,”{HOST.CONN}”,”{$NGINX.STUB_STATUS.PORT}”],1d:now/d+1d)
Ok. Algo novo aqui? Acredito que não. Porém, vale uma reflexão:
Por que estamos buscando o maior, menor e a média dos valores coletados com as funções max, min e avg, respectivamente, ao invés de utilizarmos trendmax, trendmin e trendavg? Estas últimas resgatam dados já calculados para os valores maiores, menores e para as médias de cada hora da tabela trends, ao invés de realizar todo o cálculo pelos valores resgatados da tabela history ao longo do tempo. Pense no custo operacional que essa tarefa terá quando formos calcular os valores semanais, mensais e anuais.
Contudo, há um detalhe importante: quando optamos por Trend-based Functions ao invés de History Functions, assumimos que nossas estatísticas nos retornarão valores até a última hora cheia, descartando os valores da hora atual, até que ela seja finalizada e o Zabbix faça o sincronismo da hora com o banco de dados, para iniciar o ciclo novamente. Vale conferir como a tabela de trends é gerada.
Vamos reproduzir o dashboard, desta vez, usando Trend-based Functions para as estatísticas.

Perceba que alcançamos basicamente o mesmo resultado, porém, de maneira mais eficaz e com menos esforço do Zabbix (consequentemente, exigindo menos de toda a solução e aumentando a performance de todos os cálculos envolvidos).
Insights
Se um tempo de resposta é muito pequeno, como 0.06766 (o melhor do dia), ou ainda se é muito grande, como 3.1017 (o pior do dia), imagine quais os valores possíveis entre eles (entre o mínimo e o máximo).

Como calcular uma média?
A média aritmética tradicional soma a quantidade de valores coletados em um determinado período, dividindo essa soma pela quantidade de valores.
Até aqui, ok. A função “avg” ou ainda a “trendavg” são responsáveis por gerar (ou resgatar) tais cálculos, por assim dizer. Porém, observando o gráfico acima, temos que em um determinado período, apenas em alguns momentos ocorrem “picos” do tempo de resposta, de modo que em todo o restante do tempo avaliado, a operação talvez tenha sido como esperada, ou seja, ignorando os picos, deveríamos calcular uma nova média, pois os valores mais altos, vão alterar nossa média substancialmente e talvez, não seja o cálculo adequado para mensurar como está respondendo nossa aplicação web. Contudo, também é verdade que os “picos” são importantes, pois podem significar um erro, um “desvio”, dentro do que era esperado. Tais erros ou desvios, ainda não poderiam serem considerados “anomalias” (estudaremos anomalias mais tarde).
Em estatística, os “picos” são chamados de “outliers”. Eles representam o erro, o desvio (não estamos ainda falando de desvio padrão) e são influenciadores das estimativas de localização (as médias que buscamos calcular).
As funções “avg” e “trendavg” são facilmente influenciadas pelos outliers. Então, como poderíamos criar uma estimativa robusta para a média do tempo de resposta de nossa aplicação web desconsiderando os outliers? Existem algumas saídas.
Introdução à mediana
Considere que os dados inseridos no banco de dados obedecem ao tempo de sua coleta, logo, imagine a seguinte ordem de coleta usada para criar um gráfico padrão:

Quando calcularmos a média aritmética, não importará a ordem desses valores. Porém, se organizarmos de forma crescente estes mesmos valores, podemos ter uma visão diferente:

Nesse caso, estando os valores ordenados de forma crescente, por exemplo, observamos que a mediana é exatamente o valor central do conjunto de dados observado, não tendo sido influenciada pelo outliers em questão. A linha de dados acima possui 11 posições, o que torna fácil a localização da mediana (a central, destacada de verde). Mas e se houvesse um número par de valores? Então, qual seria a mediana? Veja abaixo:

Retiramos da Tabela 1.0 o primeiro valor. Dessa forma temos 2 grupos com a quantidade de dados exatamente igual. Não há posição central.
Alguns softwares implementam algoritmos diferentes para se calcular a mediana. Alguns, por exemplo, implementam a mediana sendo a média dos dois números que representam a divisão do 1º e 2º grupo de dados. Os dois números em questão estão representados na Tabela 2.0 de verde e laranja.
Como calcular a mediana no Zabbix?
Podemos trabalhar o conceito de percentil, nesse caso. A mediana, por ser um valor central, é sinônimo do “50º percentil”.
Tome como base os valores da tabela 1.0. Crie um “Trapper item” no Zabbix e insira apenas esses valores:
0.06837, 0.0694, 0.06941, 0.06942, 0.06971, 0.06977, 0.06981, 0.07015, 0.07029, 0.07046, 3.1101
# for x in `cat numbers.txt`; do zabbix_sender -z 159.223.145.187 -s “Web server A” -k percentile.test -o “$x”; done
Ao final, teremos 11 valores na base de dados da qual queremos obter a mediana.
Em seguida, crie um Calculated item com a seguinte fórmula:
percentile(//percentile.test,#11,50)
Neste caso, nossa leitura será: observe os últimos 11 dados coletados e retorne o valor ocupa o 50º percentil. Como os valores são ímpares, é fácil fazer a conferência.

Agora, vamos trabalhar um valor par de dados e analisar quem se encaixa no percentil. Temos então a Tabela 2.0, com 10 valores. Retiramos da Tabela 1.0 o valor 0.06837:
0.0694, 0.06941, 0.06942, 0.06971, 0.06977, 0.06981, 0.07015, 0.07029, 0.07046, 3.1101
Limpe o histórico para evitar erros, ajuste a fórmula para que o percentil busque apenas os 10 últimos valores coletados e faça um novo teste.
percentile(//percentile.test,#10,50)

Curioso, obtivemos o mesmo valor. Mas existe uma explicação bem interessante.
Dado o conjunto dos 10 valores, os destacados em verde ocupam a posição de 0 a 50º percentil. E os de laranja, ocupam do 51º a 100º percentil. Veja:

Para testar e comprovar, basta alterar o último teste para resgatar quem se encaixa na posição 51º percentil.
percentile(//percentile.test,#10,51)

Perceba que o valor 0.06981 é o próximo. O primeiro da tabela, no segundo grupo de valores. Porém, se o teste for novamente alterado, por exemplo para buscarmos quem se encaixa em 55º percentil, o resultado será ainda o mesmo. Ele apenas será alterado se apontarmos a posição 61º percentil, neste caso em que temos apenas 10 valores sendo observados, logo, se avaliarmos um número maior de dados, teremos novos e diferentes resultados.
Average ou Percentile?
As duas formas de cálculos são corretas para buscar uma estimativa de localização. Contudo, é preciso entender que a primeira (average) considera os outliers, já a segunda (percentile), não. Porém, cada uma das técnicas tem uma determinada aplicação, conforme a necessidade de observação.
Vejamos uma atualização de nosso dashboard:

Não precisamos convencer ninguém sobre a métrica correta, mas exibir a informação e seu contexto.
Mediana
Se observarmos que a mediana ocupa o valor central dos dados, a fórmula de 50º percentil será útil quando a quantidade de valores observados for ímpar. No entanto, coletamos valores de tempo de resposta a cada minuto e em uma hora de observação, teremos 60 posições, provavelmente, variadas.
E se a ideia do 51º percentil puder nos fornecer o segundo valor para que a mediana então seja calculada? Fantástico. Novamente, um Calculated item:
(last(//percentile.50.input.values)+last(//percentile.51.input.values))/2
Esta é a fórmula de nossa mediana, se não quisermos arriscar utilizar o 50º percentil. Usando então os mesmos 10 valores do exercício anterior, vejamos o resultado:

Conclusão (parcial)
Neste artigo, exploramos um pouco do muito que as funções do Zabbix podem nos oferecer e muitas outras métricas e insights podem ser obtidos com estudo e dedicação.
O “Analista de Monitoramento” pode se tornar um verdadeiro “Cientista de Dados” no escopo de Tecnologia da Informação e Comunicação (TIC) e nossa ferramenta de monitoramento favorita nos apoia de várias formas!
Iniciamos nossa série com perguntas e nem todas foram respondidas. No próximo artigo, teremos mais respostas e mais insights maravilhosos.
Não se esqueça: as estimativas alcançadas com cálculos de média, mediana e percentil não são as únicas formas de se chegar a resultados, existem ainda muitos outros métodos a serem explorados, contudo, este é o início de nosso estudo.
[1] Infográfico Zabbix (unirede.net)
[1] https://www.unirede.net/zabbix-templates-onde-conseguir/
[1] https://www.unirede.net/monitoramento-de-certificados-digitais-de-websites-com-zabbix-agent2/
