

Motivação
Baseline com zabbix: Em artigos anteriores, falamos sobre ambientes recém implementados e a necessidade de planejar desde o início os cenários que podem ganhar escala junto com seu negócio ou do seu cliente. Também comentamos que monitorar um ambiente de TIC apenas aplicando templates padrões podem induzir administradores a entendimentos errôneos sobre o contexto operacional da organização. É preciso observar antes de apontar um problema. Este artigo trata exatamente esta abordagem, monitorar observando, sem alertar indiscriminadamente qualquer alteração nas métricas coletadas do ambiente.
Boa leitura!
Baseline
Baseline é o termo usado para estabelecer um padrão de comportamento. Em nosso caso, um padrão de comportamento em nosso ambiente de TIC. Como assim? Para exemplificar, vamos simplificar!
Ativo: Servidor de Intranet
Monitoramento: Tráfego da rede de dados.
Comportamento: Neste host, o tráfego de dados de entrada e saída variam conforme as atividades dos usuários da empresa, por exemplo, acessando a Intranet em vários momentos do dia, em horário administrativo.
Cenário 1: Dia normal de trabalho com matérias simples sendo publicadas, informativos.
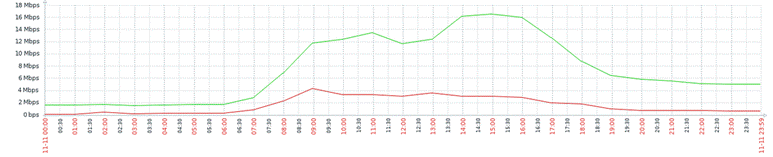
Acima, temos a seguinte leitura:
No dia 11/11/2019, terça-feira, durante o horário comercial, das 08hs às 18hs, maior tráfego de rede esteve em:
Incomming = 13.02 Mbps (tendo o valor máximo chegado à 19.47 Mbps)
Outgoing = 3.09 Mbps
Vamos tomar este valor como base e vejamos o próximo cenário.
Cenário 2: Dia normal de trabalho, porém, há uma publicação “bomba” na Intranet e todos querem ver a nova notícia.
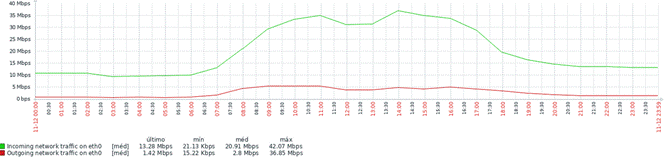
Acima, temos a seguinte leitura:
No dia 11/11/2019, terça-feira, durante o horário comercial, das 08hs às 18hs, maior tráfego de rede esteve em:
Aplicando novamente um zoom no horário comercial, vemos que as mesmas médias são:
Incomming = 31.63 Mbps (tendo o valor máximo chegado à 42.07 Mbps)
Outgoing = 4.64 Mbps
Leitura analítica inicial: no mesmo dia, 1 mês depois, vimos que o tráfego havia aumentado uma escala aproximada de 300%. Este valor não pode ser considerado normal. O que explica tal tráfego de rede?
Questão:
O que é um problema? Para dizermos que há uma anomalia no tráfego de entrada ou saída de nosso servidor de Intranet, devemos tomar como base o cenário em que não há anomalia, ou seja, já temos uma ideia de baseline por termos observado o mesmo servidor em vários momentos diferentes de um dia normal de trabalho, sendo capazes de facilmente identificar quando algo diferente acontece.
Análise:
Agora, precisamos de um gráfico único que nos informe os valores atuais, se comparados aos valores de 30 dias atrás. Não teremos, a não ser que criemos um “item calculado” com deslocamento de tempo (timeshift), para nos exibir a informação que desejamos.
Para construirmos tais itens, vamos idealizar alguns pontos:
1- Precisamos do valor atual: para este item no Zabbix, o template padrão de S.O. é capaz de realizar a coleta;
2- Qual a média do tráfego dos últimos 10 minutos?
3- Qual a média do tráfego dos últimos 10 minutos, mas há 24hs atrás (deslocamento de tempo, ou timeshift)?
4- Qual a média do tráfego dos últimos 10 minutos, mas há 7 dias atrás?
5- Qual a média do tráfego dos últimos 10 minutos, mas há 30 dias atrás?
6- Qual a média do tráfego dos últimos 10 minutos, mas há 365 dias atrás?
Vamos construir ao menos 5 itens calculados para responder às questões.
Construindo os itens calculados:
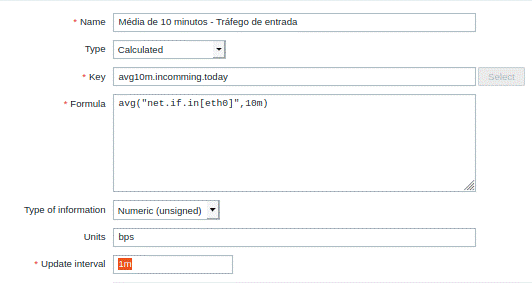
2- Média de 10 minutos dos tráfegos de entrada e saída.
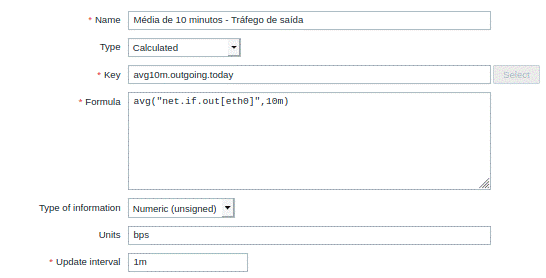
O mesmo para o tráfego de saída:
3- Média de 10 minutos, se comparados à 24 horas passadas.
As fórmulas seguem as seguintes lógicas:
avg(“net.if.in[eth0]”,10m,24h)
avg(“net.if.out[eth0]”,10m,24h)
4- Média de 10 minutos, há 7 dias atrás.
avg(“net.if.in[eth0]”,10m,7d)
avg(“net.if.out[eth0]”,10m,7d)
5- Média de 10 minutos, há 30 dias atrás.
avg(“net.if.in[eth0]”,10m,30d)
avg(“net.if.out[eth0]”,10m,30d)
6- Média de 10 minutos, há 1 ano atrás.
avg(“net.if.in[eth0]”,10m,365d)
avg(“net.if.out[eth0]”,10m,365d)
Observando
Criados os itens calculados, temos não apenas nosso monitoramento, como também nosso período de “observabilidade” dos dados coletados para fins estatísticos e avaliações. Ainda é possível criar gráficos e incluir tais itens em regras LLD de nossos templates, facilitando nossa tarefa, padronizando e normatizando nosso procedimento de observação.
Também é necessário criticar os dados, criando as triggers. Esta tarefa não será descrita aqui por diversos motivos, sendo 2 deles a particularidade de cada negócio e também a abrangência do tema, que será descrito em outro artigo.
Após a criação de alguns itens calculados, é possível receber um feedback como este:

A mensagem é clara. Criamos um item e não temos ainda dados suficientes para observar; logo que os tivermos, o item será ativado e poderemos seguir observando nosso ambiente.
Em “Monitoring/Latest data”, podemos observar o resultado do item calculado que já temos e no futuro, os próximos:
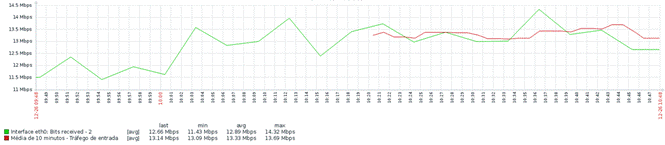
Quanto ao tráfego de entrada:
Nossa média de 10 minutos de observação é condizente com o último valor da média atual. Não há anomalias até aqui.
O mesmo para o tráfego de saída:
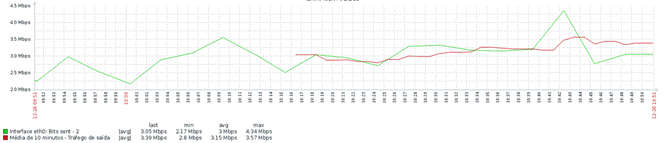
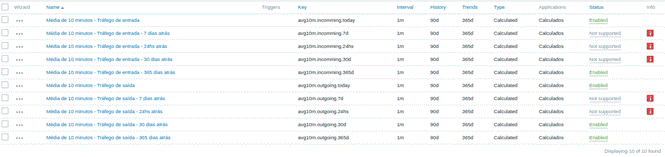
No futuro, teremos todos os itens abaixo em pleno funcionamento:
Conclusão
Podemos criar períodos de observabilidade com base em nossos interesses de monitoramento.
Por enquanto, nosso olhar clínico usará os dados do Zabbix para fazer a análise. Na versão 5.0 LTS, é previsto que o próprio Zabbix sugira a observação de anomalias com base em dados discrepantes. Vamos ficar de olho e até lá, implementar os itens calculados que podem nos auxiliar na tarefa além dos templates.
Construa gráficos, telas, altere LLDs e potencialize o uso de seu Zabbix.
Bons estudos!

Paulo R. Deolindo Jr.
Zabbix Trainer
Graduado em Tecnologia da Informação, Pós-graduado em Produção e Sistemas IFF – Instituto Federal de Educação, Ciência e Tecnologia Fluminense e pós-graduado pela Unisul (PR) no curso de Gestão de Projetos de Tecnologia da Informação. Atua confeccionando e ministrando treinamentos com foco em tecnologias Open Source, como Zabbix, Zimbra, Bacula, Gestão e Segurança em Servidores Linux, dentre outras.
- [2017] – Linux Professional Institude Certified
- [2014] – Zabbix Certified Professional
- [2014] – Zabbix Certified Specialist
- [2013] – Zimbra Collaboration Suite
